


近日,第43届国际机器学习会议(International Conference on Machine Learning, ICML 2026)正式公布论文录用结果,重点实验室沙乐天教授团队攻克大模型恶意微调安全难题。
沙乐天教授团队的研究论文《Safety Anchor: Defending Harmful Fine-tuning via Geometric Bottlenecks》顺利被ICML 2026正式录用,陆国信博士为论文第一作者,沙乐天教授为通讯作者。该成果聚焦大语言模型安全防御领域,为大模型合规化落地提供关键技术支撑。
当前大语言模型云服务场景中,模型微调阶段极易遭受恶意微调攻击,现有防御机制在持续恶意微调场景下存在明显失效问题。针对这一行业痛点,研究团队深入剖析核心症结,发现高维参数空间的固有冗余性是防御失效的根本原因:攻击者可利用与防御约束正交的优化轨迹,在规避安全限制的同时,悄悄恢复模型的有害输出能力。
面对大语言模型在微调阶段易受恶意微调攻击的安全隐患,重点实验室研究团队深入剖析了现有防御机制在持续微调下失效的根本原因。研究指出,高维参数空间的固有冗余性使得攻击者能够利用与防御约束正交的优化轨迹,在满足安全限制假象的同时恢复模型的有害输出能力。为此,该团队提出了一种名为“Safety Bottleneck Regularization”的新型防御策略。该策略将防御重点从冗余的参数空间转移到作为几何瓶颈的去嵌入层。通过将高风险查询的最终隐藏状态锚定在安全对齐模型的状态上,有效阻断了恶意能力的重建路径。
该研究聚焦于当前大模型云服务中的核心安全痛点。团队提出的SBR技术为大模型微调提供了一套“安全锁”。实验结果表明,在面对高强度的恶意微调攻击时,该技术不仅能始终将模型的风险指数控制在极低水平,还能完整保留模型原本的各项核心业务能力。这一成果为大语言模型的安全普及和合规商业化落地提供了重要的技术支撑。
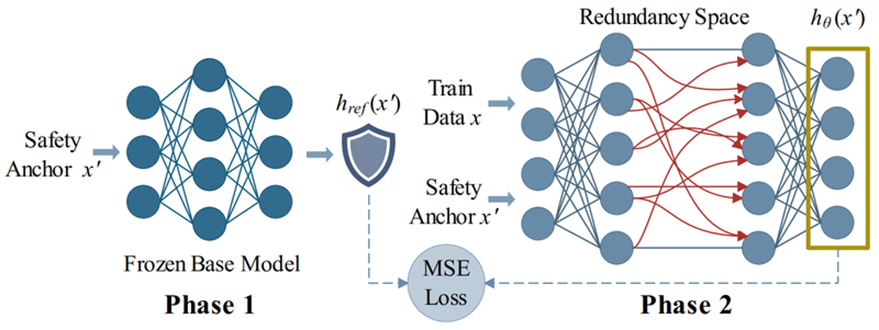
Safety Bottleneck Regularization方法框架图